

SQL 활용
WINDOW FUNCTION
서로 다른 행의 비교나 연산을 위해 만든 함수. GROUP BY를 쓰지 않고 그룹 연산 가능. LAG, LEAD, SUM, AVG, MIN, MAX, COUNT, RANK 등.
- 문법
더보기
SELECT 윈도우함수([대상]) OVER([PARTITION BY 컬럼][ORDER BY 컬럼 ASC/DESC][ROWS/RANGE BETWEEN A AND B])
PARTITION BY, ORDER BY, ROWS 등... 절 전달 순서가 중요! (ORDER BY를 PARTITION BY 전에 사용 불가.)
그룹 함수의 형태
SUM, COUNT, AVG, MIN, MAX 등. OVER 절을 사용하여 윈도우 함수로 사용 가능. 반드시 연산할 대상을 그룹함수의 입력값으로 전달.
- SUM OVER() / COUNT OVER() / AVG OVER() / MIN OVER() / MAX OVER() 등 동일한 문법 사용.
각 직원 정보와 급여 총 합(그룹함수 결과)을 동시에 출력 시도 시 에러 발생.
해결: 서브쿼리 사용(스칼라 서브쿼리), 윈도우 함수 사용
- 윈도우 함수의 연산 범위 : 집계 연산 시 행의 범위 설정 가능!
1. ROWS, RANGE 차이
ROWS : 값이 같더라도 각 행씩 연산.
RANGE : 같은 값의 경우 하나의 RANGE로 묶어서 동시 연산. (DEFAULT)
2. BETWEEN A AND B
A) 시작점 정의
CURRENT ROW : 현재 행부터
UNBOUNDED PRECEDING : 처음부터(DEFAULT)
N PRECEDING : N 이전부터
B) 마지막 시점 정의
CURRENT ROW : 현재 행까지(DEFAULT)
UNBOUNDED FOLLOWING : 마지막까지
N FOLLOWING : N 이후까지
순위 관련 함수
- RANK(순위)
- RANK WITHIN GROUP: 특정값에 대한 순위 확인.(RANK WITHIN) 윈도우 함수가 아닌 일반 함수.
- RANK() OVER(): 전체 / 특정 그룹 중 값의 순위 확인. ORDER BY 절 필수. 순위를 구할 대상을 ORDER BY 절에 명시.(여러 개 나열 가능) 특정 그룹 내 순위 구할 시 PARTITION BY 절 사용.
- DENSE_RANK: 누적 순위. 값이 같을 때동일한 순위 부여 후 다음 순위가 바로 이어지는 순위 부여 방식. ex. 1등이 5명이더라도 그 다음 순위가 2등이 된다.
- ROW_NUMBER: 연속된 행 번호. 동일한 순위를 인정하지 않고단순히 순서대로 나열한 순서 값 리턴.
RANK, DENSE_RANK, ROW_NUMBER 비교.
문법
SELECT ENAME, DEPTNO, SAL,
RANK() OVER(ORDER BY SAL DESC) AS RANK_VALUE1,
DENSE_RANK() OVER(ORDER BY SAL DESC) AS RANK_VALUE2,
ROW_NUMBER() OVER(ORDER BY SAL DESC) AS RANK_VALUE3
FROM EMP- 동순위 처리
RANK, DENSE_RANK의 경우 : 동일한 값이라면 동일한 순위
ROW_NUMBER의 경우 : 동일한 값이라도 순위가 다르게 나열. (위의 경우 SAL 내림차순으로 순위 처리) - 후순위 처리
RANK의 경우 : 동순위에 몇 개가 처리되었냐에 따라 후순위가 달라진다. (1등이 2명이라면 2등이 없고 3등부터.)
DENSE_RANK의 경우 : 동순위가 몇 개라도 다음 순위가 나온다. (1등이 2명이라도 3번째 데이터가 2등이 된다.)
ROW_NUMBER의 경우 : 동순위를 인정하지 않으므로 그저 순서대로 나열된다.
LAG, LEAD
행 순서대로 각각 이전 값(LAG), 이후 값(LEAD) 가져오기. ORDER BY절 필수.
FIRST_VALUE, LAST_VALUE
정렬 순서대로 정해진 범위에서의 처음 값, 마지막 값 출력. 순서와 범위 정의에 따라 최솟값과 최댓값 리턴 가능. PARTITION BY, ORDER BY 절 생략 가능.
LAST_VALUE의 경우 마지막 데이터를 리턴하므로 RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING (처음부터 마지막까지) 전체 데이터로 범위를 지정해줄 필요가 있다.
NTILE
행을 특정 컬럼 순서에 따라 정해진 수의 그룹으로 나누기 위한 함수. 그룹 번호가 리턴. ORDER BY 필수. PARTITION BY를 사용하여 특정 그룹을 또 원하는 수만큼 그룹 분리 가능. 총 행의 수가 명확히 나눠지지 않을 때 앞 그룹의 크기가 더 크게 분리된다. ex. 14명 3개의 그룹 분리 시 → 5 5 4로 나뉜다.
비율 관련 함수
- RATIO_TO_REPORT: 각 값의 비율 리턴.(전체 비율 또는 특정 그룹 내 비율 가능) ORDER BY 사용 불가.
- CUME_DIST: 각 행의 수에 대한 누적비율. 특정 값이 전체 데이터 집합에서 차지하는 위치를 백분위수로 계산하여 출력.ORDER BY 를 사용하여 누적비율 구하는 순서를 정할 수 있다. ORDER BY 필수. 값이 3개이면 1/3 = 0.33부터 시작.
- PERCENT_RANK: PERCENTILE(분위수) 출력. 전체 COUNT 중 상대적 위치 출력(0~1 범위 내). ORDER BY 필수.
CUME_DIST 와 PERCENT_RANK 비교
SELECT CUME_DIST() OVER (ORDER BY SAL) AS CUME_DIST,
PERCENT_RANK() OVER (ORDER BY SAL) AS PERCENT_RANK,
SAL
FROM EMP
WHERE DEPTNO = 10
- 데이터가 3개일 경우: CUME_DIST는 0.3333333333 / 0.66666666 / 1 이런 식의 데이터가 차지하는 비율을 출력하고, PERCENT_RANK는 0 / 0.5 / 1 이렇게 분위수를 출력한다.
TOP N QUERY
페이징 처리를 효과적으로 수행하기 위해 사용. 전체 결과에서 특정 N개 추출. ex. 성적 상위자 3명.
TOP N 행 추출 방법
- ROWNUM
- RANK
- FETCH
- TOP N(SQL Server)
ROWNUM
출력된 데이터 기준으로 행 번호 부여. 절대적인 행 번호가 아닌 가상의 번호이므로 특정 행을 지정할 수 없다.(=연산 불가) 첫번째 행이 증가한 이후 할당되므로 > 연산 사용 불가.(0은 가능)
크다 조건 전달 불가. 항상 불변하는 절대적 번호가 아니므로 = 연산자 단독 전달 불가.
Equal 비교 시 작다(<) 와 함께 사용하면 1부터 순서대로 뽑을 수 있기 때문에 출력 가능. 정렬 순서에 따라 출력되는 ROWNUM이 달라진다.
FETCH 절
출력될 행의 수를 제한하는 절. ORACLE 12C 이상부터 제공.(이전 버전에는 ROWNUM을 주로 사용했다.) SQLServer 사용 가능. ORDER BY 절 뒤에 사용.(내부 파싱 순서도 ORDER BY 뒤)
- 문법
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
OFFSET N { ROW | ROWS }
FETCH { FIRST | NEXT } N { ROW | ROWS } ONLY- OFFSET : 건너뛸 행의 수. ex) 성적 높은 순 1등 제외, 나머지 3명.
- N : 출력할 행의 수.
- FETCH : 출력할 행의 수를 전달하는 구문.
- FIRST : OFFSET을 쓰지 않았을 때 처음부터 N행 출력 명령.
- NEXT : OFFSET을 사용했을 경우 제외한 행 다음부터 N행 출력 명령.
- ROW | ROWS : 행의 수에 따라 하나일 경우 단수, 여러 값이면 복수형.(특별히 구분하지 않아도 된다.)
TOP N 쿼리
SQL Server에서의 상위 N개 행 추출 문법. 서브쿼리 사용 없이 하나의 쿼리로 정렬된 순서대로 상위 N개 추출 가능. WITH TIES를 사용하여 동순위까지 함께 출력 가능.
계층형 질의
하나의 테이블 내 각 행끼리 관계를 가질 때, 연결고리를 통해 행과 행 사이의 계층(Depth)을 표현하는 기법. ex. DEPT2에서의 부서별 상하관계. PRIOR의 위치에 따라 연결하는 데이터가 달라진다.
- 문법
SELECT 컬럼명
FROM 테이블명
START WITH 시작조건 -- 시작점을 지정하는 조건 전달
CONNECT BY [NOCYCLE] PRIOR 연결조건 -- 시작점 기준으로 연결 데이터를 찾아가는 조건- START WITH : 데이터를 출력할 시작 지정하는 조건.
- CONNECT BY PRIOR : 행을 이어나갈 조건.
- NOCYCLE : 순환이 발생하면 무한 루프가 될 수 있기 때문에 이를 방지하고자 사용.
계층형 질의 가상 컬럼
- LEVEL : 각 DEPTH를 표현. (시작점부터 1)
- CONNECT_BY_ISLEAF : LEAF NODE(최하위노드) 여부. (참 : 1, 거짓 : 0)
계층형 질의 가상 함수
- CONNECT_BY_ROOT 컬럼명: 루트노드에 해당하는 컬럼값.
- SYS_CONNECT_BY_PATH(컬럼, 구분자) : 이어지는 경로 출력.
- ORDER SIBLINGS BY 컬럼 : 같은 LEVEL일 경우 정렬 수행.
- CONNECT_BY_ISCYCLE : 계층형 쿼리의 결과에서 순환이 발생했는지 여부.
데이터의 구조
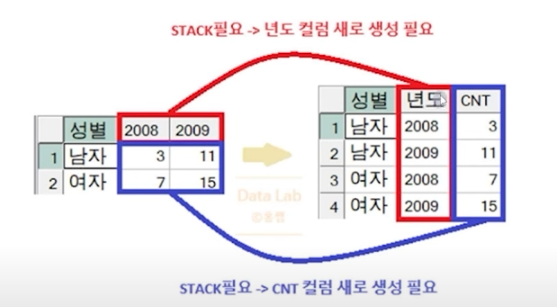
- LONG DATA(Tidy data): 하나의 속성이 하나의 컬럼으로 정의되어 값들이 여러 행으로 쌓이는 구조. RDBMS의 테이블 설계 방식. 다른 테이블과의 조인 연산이 가능한 구조.
- WIDE DATA(Cross table): 행과 컬럼에 유의미한 정보 전달을 목적으로 작성하는 교차표. 하나의 속성값이 여러 컬럼으로 분리되어 표현. RDBMS에서 WIDE 형식으로 테이블 설계시 값이 추가될 때마다 컬럼이 추가되어야 하므로 비효율적! 다른 테이블과의 조인 연산이 불가. 주로 데이터를 요약할 목적으로 사용.
데이터 구조 변경
- PIVOT : LONG → WIDE
데이터를 펼친다고 생각! - UNPIVOT : WIDE → LONG
데이터를 컬럼으로 늘어뜨린다!
PIVOT
교차표를 만드는 기능. STACK 컬럼, UNSTACK 컬럼, VALUE 컬럼의 정의가 중요. FROM절에 STACK, UNSTACK, VALUE 컬럼명만 정의 필요.(필요 시 서브쿼리 사용하여 필요 컬럼 제한.) PIVOT절에 UNSTACK, VALUE 컬럼명 정의. PIVOT절 IN연산자에 UNSTACK 컬럼 값을 정의. FROM 절에 선언된 컬럼 중 PIVOT 절에서 선언한 VALUE 컬럼, UNSTACK 컬럼을 제외한 모든 컬럼은 STACK 컬럼이 된다.

- 문법
SELECT *
FROM 테이블명 | 서브쿼리
PIVOT (VALUE컬럼명 FOR UNSTACK컬럼명 IN (값1, 값2, 값3))반드시 FROM 절에 STACK컬럼, UNSTACK컬럼, VALUE컬럼 모두 명시.
UNPIVOT
WIDE 데이터를 LONG 데이터로 변경하는 문법.
STACK컬럼: 이미 UNSTACK되어 있는 여러 컬럼을 하나의 컬럼으로 STACK 시 새로 만들 컬럼이름. (사용자 정의)
VALUE컬럼: 교차표에서 셀 자리(VALUE)값을 하나의 컬럼으로 표현하고자 할 때 새로 만들 컬럼명. (사용자 정의)
값1, 값2...: 실제 UNSTACK 되어 있는 컬럼 이름들.
만약 컬럼이 숫자형이면 쌍따옴표로 묶어서 전달. - IN 뒤의 값은 UNSTACK 데이터의 컬럼명이 숫자이지만 컬럼명은 문자로 저장되므로 쌍따옴표 전달 필수.
정규 표현식
문자열의 공통된 규칙을 보다 일반화하여 표현하는 방법. 정규 표현식 사용 가능한 문자함수 제공. (regexp_replace, regexp_substr, regexp_instr...) ex. 숫자를 포함하는 숫자로 시작하는 4자리, 두번째 자리가 A인 5글자.
정규 표현식 종류

_는 단어에 속한다.
ex.
글자 : tel)02-999-4456 → 1차 일반화 : tel∖)[0-9-]+ → 2차 일반화 tel∖)?[0-9-]+
글자 : tel02-999-4456 → 1차 일반화 : tel[0-9-]+ → 2차 일반화 tel∖)?[0-9-]+
regexp_replace
정규식 표현을 사용한 문자열 치환 가능.
- 특징
바꿀 문자열 생략 시 문자열 삭제.
검색위치 생략 시 1.
발견횟수 생략 시 0 (모든). - 옵션
c : 대소를 구분하여 검색.
i : 대소를 구분하지 않고 검색.
m : 패턴을 다중라인으로 선언 가능.
. 이 모든 글자를 의미한다는 것을 기억하자.
regexp_substr
정규식 표현식을 사용한 문자열 추출. 옵션은 REGEXP_SUBSTR 과 동일.
- 특징
검색위치 생략 시 1.
발견횟수 생략 시 1.
추출그룹은 서브패턴을 추출 시 그 중 추출할 서브패턴 번호.
regexp_instr
주어진 문자열에서 특정패턴의 시작 위치를 반환. 옵션은 REGEXP_SUBSTR과 동일.
- 특징
검색위치 생략 시 처음부터 확인 (기본값 : 1).
발견횟수 생략 시 처음 발견된 문자열 위치 리턴.
\d는 숫자를 나타내는 표현이고, 뒤에 횟수를 지정하지 않으면 한 자리 수의 숫자를 의미.
regexp_like
주어진 문자열에서 특정패턴을 갖는 경우 반환.(WHERE절 사용만 가능) 옵션 REGEXP_REPLACE와 동일.
$ : 마지막 문자.
regexp_count
주어진 문자열에서 특정패턴의 횟수를 반환. 옵션 REGEXP_REPLACE와 동일.
\d는 한 자리 수 문자 의미, \d+는 연속적인 숫자를 의미하기 때문에 COUNT 시 연속적인 숫자를 하나로 취급한다.
